Golden Master legacy testing - where does the test data come from?
I get the question from now to then "When using the Golden Master testing technique, how do you generate data?". In particular the concern is to have relevant data.
Now in a kata like the Legacy Code Retreat (trivia) and other small pieces of code, you can usually generate random data - this works particularly well with the trivia code as it depends on a randomizer already. Because this randomizer is the only input data the code depends on, you get 100% coverage if you vary it.
However randomly generating data is not always feasible or at least not easy. So what do you do then? Here's what I've been using, the list is non exhaustive of course. Please help me think of other means!
- Capture production data
- Ask a product expert
- Use code coverage
- Generating data (not so randomly)
Capture production data
 This is my favorite. It is usually possible to ask for it, after all it is a legacy system in production and many people depend on it so if you say it might blow up on next delivery ... well people tend to find ways to get that data. There are a million ways of capturing it : listening to network traffic, looking in the database, looking in logs. Even inside the application you can serialize an object (in java with XStream for instance), well that is if you can push this kind of patch to production or duplicate network traffic to a second instance that is not in production.
This is my favorite. It is usually possible to ask for it, after all it is a legacy system in production and many people depend on it so if you say it might blow up on next delivery ... well people tend to find ways to get that data. There are a million ways of capturing it : listening to network traffic, looking in the database, looking in logs. Even inside the application you can serialize an object (in java with XStream for instance), well that is if you can push this kind of patch to production or duplicate network traffic to a second instance that is not in production.
The extra benefit with this method is that you can discover dead code and delete it :-D
How do you decide how much data is enough? Usually I collect A LOT, too much to work with. Then I run it all, verify I get close to total coverage, then i remove data until the code coverage gets affected.
This is my favorite. It is usually possible to ask for it, after all it is a legacy system in production and many people depend on it so if you say it might blow up on next delivery ... well people tend to find ways to get that data. There are a million ways of capturing it : listening to network traffic, looking in the database, looking in logs. Even inside the application you can serialize an object (in java with XStream for instance), well that is if you can push this kind of patch to production or duplicate network traffic to a second instance that is not in production.Ask a product expert
This wont provide all significant data, but it is a start in understanding the code and data . If you run the application with this data and analyse what is not covered chances are you can complete the picture with "invented" data. Sharing these findings with the product expert can be quite interesting.
Use code coverage
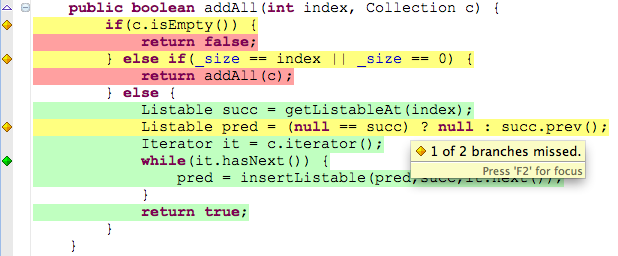 Write a first test, check the code coverage. Examine the code to find out how to cover the next branch,
Write a first test, check the code coverage. Examine the code to find out how to cover the next branch,
write the test, validate you assumption by running the code coverage. Repeat until done.
Write a first test, check the code coverage. Examine the code to find out how to cover the next branch,write the test, validate you assumption by running the code coverage. Repeat until done.
Aucun commentaire:
Enregistrer un commentaire